
در بخش اول در مورد ساختار کلی سیستم تشخیص اشیاء YOLO صحبت کردیم و حالا ادامه مطلب را پی می گیریم.
آموزش شبکه
آموزش شبکه تشخیص اشیای YOLO در دو مرحله مجزا انجام میشود:
ابتدا، شبکه YOLO با پایگاه داده ۱۰۰۰ کلاسه ImageNet برای عمل کلاسبندی آموزش داده شده است. در این فرآیند آموزش، از ۲۰ لایه کانولوشنی ابتدایی YOLO استفاده شده است. در انتهای این ۲۰ لایه، یک لایه پولینگ میانگین (Average Pooling) و یک لایه فولیکانکتد قرار گرفته است. تصاویر ورودی در اندازه ۳×۲۲۴×۲۲۴ به شبکه داده شدهاند. این شبکه تقریبا بهمدت یک هفته آموزش داده شده که درنهایت دقت ۸۸% در top-۵ در ImageNet حاصل شده است.
در مرحله دوم، برای کار تشخیص اشیا در ساختار مدل تغییراتی ایجاد شده است. تغییرات به اینصورت است که چهار لایه کانولوشنی و دو لایه فولی کانکتد با وزنهای تصادفی به انتهای ۲۰ لایه شبکه اضافه شده است. در کار تشخیص اشیا اغلب به اطلاعات با جزئیات بیشتری نیاز است، بههمین دلیل رزولوشن ورودی شبکه از ۳×۲۴۴×۲۲۴ به ۳×۴۴۸×۴۴۸ افزایش داده شده است. بنابراین، به جواب یکی از سوالها رسیدیم و متوجه شدیم که هدف از افزایش اندازه ورودی، بهرهگیری از جزئیات بیشتر در تصویر است.
درمورد ورودی شبکه توضیح داده شد، حال نوبت به بررسی خروجی شبکه است. اندازه خروجی شبکه ۳۰×۷×۷ است. ابتدا از اندازه ۷×۷ شروع کنیم؛ تصاویر ورودی به یک شبکه ۷×۷ تقسیمبندی میشوند (در شکل ۴ نشان داده شده است). بنابراین، خروجی ۷×۷ متناظر با تصویر شبکهشده ورودی است. هر درایه در ۷×۷ خروجی، متناظر با یک سلول در تصویر شبکهشده ورودی است (شکل ۴)
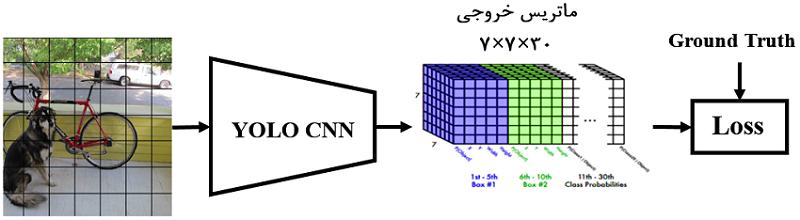
شکل ۴
هر درایه از این ماتریس ۷×۷ خروجی یک بردار بهطول ۳۰ دارد (شکل ۶). این بردار بهطول ۳۰ شامل اطلاعات پیشبینی احتمالها و مختصات باکس است. اما چگونه؟ هر سلول از این آرایه ۷×۷ دو باکس میتواند رسم کند. برای رسم هر باکس به ۵ پارامتر (x,y,w,h,confidence) نیاز است. پارامترهای x و y، مختصات سطر و ستون مبدا باکس (مرکز باکس) را نشان میدهند. مختصات w و h بهترتیب متناظر با پهنا و ارتفاع باکس هستند. با این چهار پارامتر میتوانیم باکس را ترسیم کنیم، درحالیکه گفتیم ۵ پارامتر برای ترسیم باکس نیاز است. پارامتر پنجم چه کاربردی دارد؟ پارامتر پنجم confidence هست؛ یک پارامتر احتمالاتی با مقدار بین ۰ تا ۱ که میگوید اصلا این باکس شامل شی هست یا اینکه پسزمینه تصویر است! طبیعتا ما باکسهایی را میخواهیم که مقدار بزرگی داشته باشند که نشان میدهد این باکس شامل یک شی است. مقدار confidence از طریق رابطه IoU بین باکس پیشبینی و باکس واقعی محاسبه میشود.
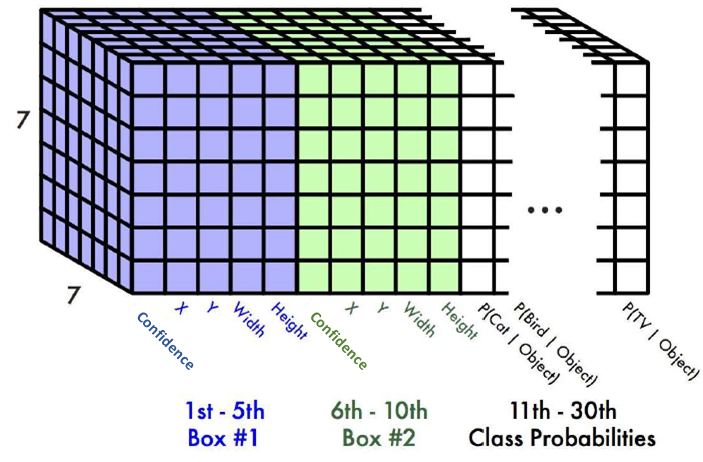
شکل ۶: تنسور سهبعدی خروجی YOLO که اعداد ۷ نشاندهنده سطر و ستون هست. همچنین، هر درایه در ۷×۷ یک بردار بهطول ۳۰ دارد
تابع اتلاف
در YOLO از تابع اتلاف MSE یا Mean Squared Error استفاده شده است، چون بهینهسازی این تابع اتلاف آسان است و با مساله رگرسیون که در YOLO مطرح شده سازگار است. پلی به گذشته میزنیم و یادآوری میکنیم که در این مقاله بارها گفته شد که YOLO به مساله تشخیص اشیا بهصورت رگرسیون مینگرد. حال اینجا هم خروجی شبکه را مشاهده کردید و هم اینکه تابع اتلاف MSE خود نشاندهنده دلیل رگرسیون هست. اما لازم است در تابع اتلاف MSE تغییراتی ایجاد شود که بیشتر با خواسته ما برای تشخیص اشیا همراستا باشد. تابع اتلاف نهایی در YOLOv۱ بهشکل زیر است:
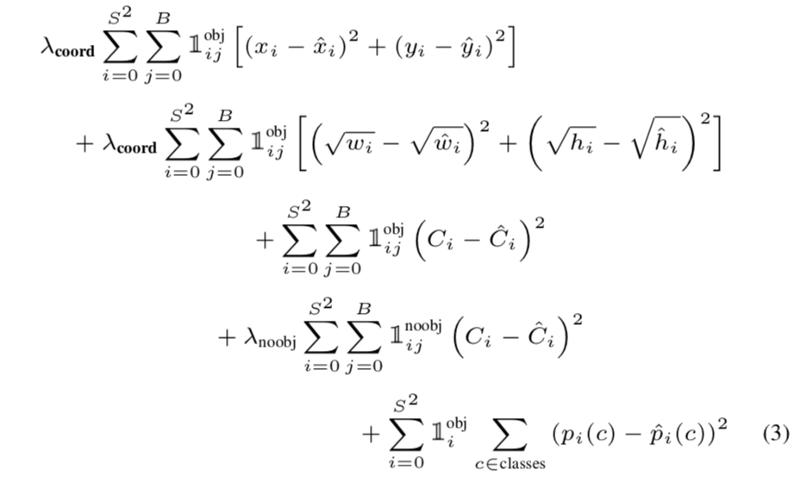
بیایید از ابتدا، خطبهخط تابع اتلاف YOLO را بررسی کنیم؛ در خط اول، با استفاده از رابطه SSE، موقعیت مبداهای دو باکس پیشبینی و واقعی (x,y) باهم مقایسه شدهاند. اندیسهای i و j بهترتیب نشاندهنده سلولها (۴۹ سلول داریم) و باکسها (B) هستند. پشت سیگما یک متغیر ۱obj لحاظ شده است؛ درصورتی ۱ هست که باکس j در سلول i شامل یک شی باشد، درغیراینصورت صفر خواهد بود. سلولی که شامل باکسی باشد که شی در آن وجود ندارد و شامل پسزمینه باشد، چه ارزشی برای ما دارد. دو سیگما داریم که وظیفهشان بررسی تکتک سلولها و باکسها هست. پشت سیگماها هایپرپارامتر λ قرار دارد. این پارامتر را به ذهن بسپارید تا در آخر درباره آن توضیح دهیم.
در خط دوم، رابطه تقریبا مشابهی با خط اول میبینیم. اما بجای x و y از w و h استفاده شده است. یعنی در اینجا میخواهیم پهنا و ارتفاع باکس پیشبینی را با باکس واقعی مقایسه کنیم. اما چرا w و h داخل یک √ قرار دارند؟ به این سوال فکر کنید و جواب آن را بیابید و بعد درادامه پاسخ آن را بخوانید. جواب آن بسیار ساده و جالب است؛ در تصویر، اشیای با اندازههای مختلف از خیلی کوچک تا خیلی بزرگ داریم. حالا وقتیکه بخواهیم باکسهای این اشیا را با باکسهای واقعی مقایسه کنیم، همه باکسها با هر اندازهای را با یک معیار مقایسه میکنیم. درحالیکه میدانیم خطا در باکسهای بزرگ مانند خطا در باکسهای کوچک نیست. بهعبارت دیگر، یک پیکسل خطا در باکس بزرگ باید کمتر مجازات داشته باشد تا یک پیکسل خطا در باکس کوچک. با استفاده از √، ما باکسهای بزرگ را کمتر از باکسهای کوچک مجازات میکنیم. کافیاست نمودار y=x و y=√x را باهم مقایسه کنید.
خط سوم و چهارم، ضریب اطمینان (Confidence) برای حضور یا عدم حضور یک شی در باکس هست. اول اینکه، خط سوم برای ضرایب اطمینان باکسهایی است که شامل شی هستند و خط چهارم متناظر با باکسهایی است که شامل هیچگونه شی نیستند. پشت سیگماهای خط چهارم، یک هاپیرپارامتر λ قرار داده شده است. مقدار این پارامتر ۰.۵ درنظر گرفته شده است. چرا؟ چون، در هر تصویر بسیاری از باکسها شامل شی نیستند و تعداد باکسهای بدون شی بیشتر از با شی هست. برای اینکه مقدار اتلاف باکسهای بدون شی بر باکسهای با شی غلبه نداشته باشد، ضریب ۰.۵ پشت آن قرار داده شده تا مقدار اتلاف باکسهای بدونشی کاهش یابد. درنهایت، مقدار احتمال کلاسها باهم مقایسه شدهاند.
بسیار خوب، بخش نسبتا سخت تابع اتلاف را هم بهپایان رساندیم. در بخش بعدی میخواهیم ببینیم تنظیمات لازم برای آموزش شبکه چگونه است. این بخش مهم است، چون به ما میآموزد شبکههای خود را با چه تنظیماتی آموزش دهیم.
تنظیمات آموزش شبکه
شبکه به اندازه ۱۳۵ ایپوک با دادههای Train و Validation از پایگاه داده PASCAL VOC ۲۰۰۷ و ۲۰۱۲ آموزش داده شده است. هنگام تست روی پایگاه داده PASCAL VOC ۲۰۱۲، از دادههای تست PASCAL VOC ۲۰۰۷ هم برای آموزش استفاده شده است. برای آموزش از تنظیمات Batch size=۶۴، Momentum=۰.۹ و Weight decay=۵e-۴ استفاده شده است.
برنامه lr به اینصورت است که، برای ایپوکهای اولیه، به صورت آرام نرخ یادگیری از ۰.۰۰۱ تا ۰.۰۱ افزایش مییابد (دقت کنید به این فرآیند که نرخ یادگیری از مقدار کوچکی شروع و سپس بهآرامی زیاد شود، warmup گفته میشود که تکنیک بسیار خوبی برای آموزش در ایپوک های اولیه است. چون شبکه در ابتدای فرآیند آموزش درحالت ناپایدار قرار دارد و بنابراین بهتر است نرخ یادگیری کم باشد و سپس بهآرامی زیاد شود). سپس، آموزش شبکه با نرخ یادگیری ۰.۰۱ به اندازه ۷۵ ایپوک ادامه یافته است، سپس برای ۳۰ ایپوک نرخ یادگیری ۰.۰۰۱ خواهد بود و درنهایت برای ۳۰ ایپوک ۰.۰۰۰۱ خواهد شد.
برای جلوگیری از Overfitting، از Dropout و دادهسازی (Data Augmentation) استفاده شده است. از Dropout با نرخ ۰.۵ بعد از لایههای فولیکانکتد استفاده شده است. برای دادهسازی هم، مقیاس (Scale) و انتقال (Translation) حداکثر ۲۰% اندازه تصویر اصلی بهکار برده شده است. همچنین، به صورت تصادفی Exposure و Saturation در تصویر با فاکتوری حداکثر ۱.۵ در فضای رنگی HSV تنظیم شده است.
آزمایش
پس از فرآیند آموزش YOLO، مشاهده خروجی YOLO برای یک تصویر نمونه بسیار ساده است. یک تصویر نمونه به ابعاد ۳×۴۴۸×۴۴۸ بهعنوان ورودی به شبکه داده میشود و شبکه احتمالها و مختصات باکسها را پیشبینی میکند. این خروجیها در قالب یک ماتریس ۳۰×۷×۷ برای پایگاه داده PASCAL VOC ارائه میشوند. برای هر سلول در ماتریس ۷×۷، دو باکس وجود دارد و درمجموع هم ۴۹ سلول داریم. بنابراین، بهاندازه ۴۹×۲ باکس در تصویر میتوانیم رسم کنیم. یعنی برای هر تصویری ۹۸ باکس در خروجی ترسیم میشود؟! خیر، حداکثر ۹۸ باکس میتوانیم داشته باشیم، اما با روشهای آستانهگیری و حذف غیرحداکثرها (Non-maximal Supression) بسیاری از این ۹۸ باکس حذف میشوند.
محدودیتهای YOLO
باوجود دستاوردهای بزرگی که شبکه YOLO بههمراه داشته است، اما با محدودیتها و چالشهایی هم همراه است. درادامه، به تعدادی از این محدودیتها اشاره شده است:
• اگرچه YOLO دو باکس برای هر سلول ترسیم میکند، اما این باکس از دو کلاس مختلف هستند. یعنی در هر سلول، از یک کلاس دو باکس نمیتواند رسم کند. چرا؟ راهنمایی: به بردار ۳۰-تایی هر سلول ۷×۷ توجه کنید.
• YOLO در تشخیص اشیای کوچک در تصویر، مانند دسته پرندگان چالش دارد.
• YOLO در تشخیص اشیای با ابعاد جدید و غیرمعمولی که در فرآیند آموزش ندیده باشد، مشکل دارد.
• YOLO از ویژگیهای کلی اشیا برای تشخیص بهره میبرد، چون تنها از ویژگیهای لایه خروجی برای تشخیص اشیا استفاده میکند که این ویژگیها کلی هستند و بهخاطر کوچک شدنهای متوالی جزئیات از بین میروند. بهنظر شما چاره کار چیست؟
• بهنظر شما YOLO چه چالشها و محدودیتهای دیگری دارد؟
نتایج ارزیابی
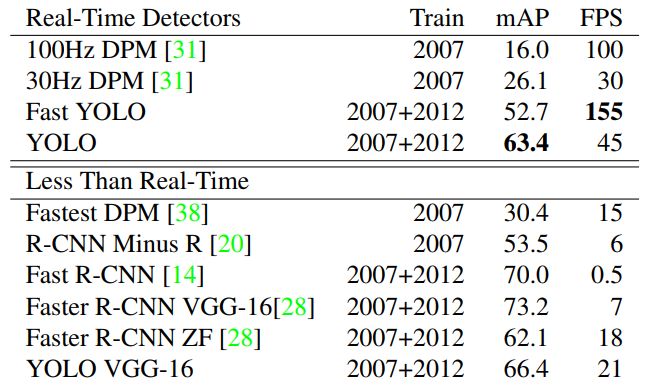
بهتر است ابتدا به یکی از مهمترین نقطه قوتهای YOLO، یعنی سرعت بپردازیم. در جدول زیر، نتایج مقایسه سرعت و دقت YOLO با سایر کارها را مشاهده میکنید. جدول از دو بخش Real-Time Detectors و Less Than Real-Time تشکیل شده است. بخش اول (Real-Time Detectors)، الگوریتمهای تشخیص اشیای سریع را نشان میدهد؛ در این بخش، مشاهده میکنید که Fast YOLO و YOLO هردو هم سرعت بسیار بالا (FPS) و هم دقت بالاتر (mAP) نسبت به ۱۰۰Hz DPM و ۳۰Hz DPM دارند.
بخش دوم (Less Than Real-Time) مربوط به الگوریتمهایی میشود که بلادرنگ نیستند (سریع نیستند). دراینجا بجای YOLO از YOLO VGG-۱۶ استفاده شده است. در YOLO VGG-۱۶ از شبکه VGG-۱۶ برای تشخیص اشیا بجای مدل ۲۴ لایهای YOLO استفاده شده است. VGG-۱۶ دقت بهتری دارد، اما سرعت پایینتری دارد. دراینحالت، سرعت YOLO به ۲۱ فریمبرثانیه افت کرده، اما بازهم بهتر از سایر الگوریتمهاست. درعینحال، در بخش mAP نسبت به بعضی الگوریتمها مانند Fast R-CNN کمی ضعیفتر است. البته دقت کنید همین Fast R-CNN، سرعت پردازش ۰.۵ فریمبرثانیه دارد!
بخش بعدی ارزیابی، مربوط به مقایسه دقیق بین YOLO و Fast R-CNN هست. دراینجا، برای تشخیص اشیا، خطاهای مختلفی تعریف شده و سپس اندازهگیری شده که هریک از این دو الگوریتم چقدر خطا دارند. در شکل زیر، نمودار دایرهای تحلیل خطا بین YOLO و Fast R-CNN رو مشاهده میکنید. بهصورت خلاصه، نمودار شکل ۷ را بهصورت زیر میتوان مقایسه نمود:
• correct: اگر کلاس شی درست تشخیص داده شده باشد و مقدار IOU بزرگتر از ۰.۵ باشد. دراین مورد، Fast R-CNN عملکرد بهتری دارد (ناحیه سبز).
• localization: اگر کلاس شی درست تشخیص داده شده باشد ولی مقدار IOU بین [۰.۵ ۰.۱] باشد. دراین خطا، عملکرد Fast R-CNN بهتر است (ناحیه آبی).
• Background: مقدار IOU کمتر از ۰.۱ باشد. در این خطا، عملکرد YOLO بهتر است.
با بررسی سه مورد بالا، میتوان به این نتیجه رسید که عملکرد Fast R-CNN درکل بهتر از YOLO است. YOLO خطای بیشتری در موقعیتیابی اشیا دارد و این یک چالش برای YOLO محسوب میشود. اما درعینحال، YOLO خطای پسزمینه کمتری نسبت به Fast R-CNN دارد.

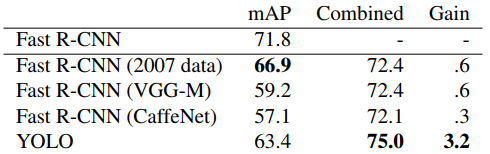
ترکیب Fast R-CNN و YOLO هم میتواند جالب باشد. YOLO خطاهای پسزمینه کمتری نسبت به Fast R-CNN تولید میکند. با استفاده از YOLO برای حذف تشخیصهای پسزمینه از Fast R-CNN، میتوانیم بهبود قابلتوجهی در کارآیی تشخیص اشیای Fast R-CNN ایجاد کنیم. اما چگونه این دو را ترکیب کنیم؟ برای هر باکسی که توسط Fast R-CNN پیشبینی میشود، چک میکنیم که آیا YOLO باکس مشابهی پیشبینی کرده است یا خیر. درصورت پاسخ بله، پیشبینی از طریق احتمال YOLO تقویت میشود و همچنین همپوشانی (overlap) بین دو باکس محاسبه و بهعنوان باکس نهایی نمایش داده میشود. در جدول زیر، مشاهده میکنید که Fast R-CNN با مدلهای مختلفی ترکیب شده و بهترین mAP متعلق به ترکیب Fast R-CNN با YOLO است (روشی ترکیبی به mAP=۷۵% دست یافته است.
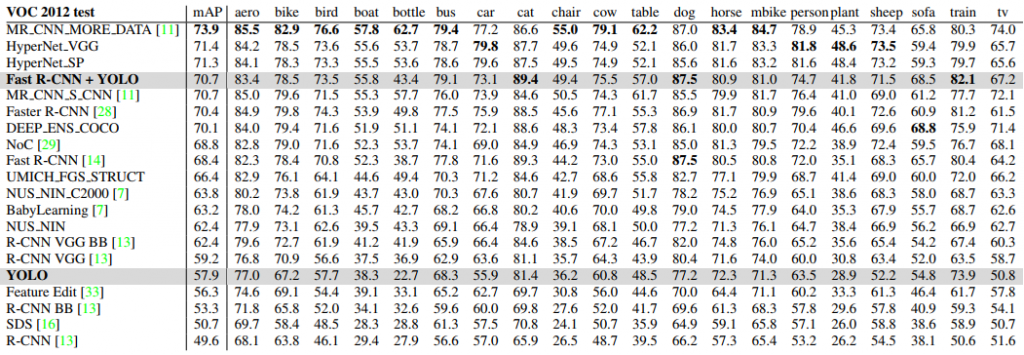
YOLO در مجموعه تست پایگاه داده VOC ۲۰۱۲، به mAP ۵۷.۹% رسیده است. باتوجه به جدول زیر، این مقدار پایینتر از بهترین نتایج ارائه شده در حال حاضر است و نزدیک به R-CNN با استفاده از VGG-۱۶ است. در مقایسه با رقیبهای نزدیک مانند R-CNN، سیستم YOLO بیشتر درگیر چالش تشخیص اشیای کوچک است. بهعنوان مثال، YOLO در تشخیص اشیایی مانند bottle، sheep و tv/monitor عملکردی ۸-۱۰% پایینتر نسبت به R-CNN دارد. اما، در سایر کلاسها مانند گربه، YOLO عملکرد بهتری در تشخیص دارد. در بخش قبل، YOLO با Fast R-CNN ترکیب شد که مشاهده میکنید این مساله باعث شده که دقت بالایی حاصل شود و رتبه پنجم در جدول را دارد. البته، دراینحالت دیگر باید از مقوله سرعت که از ویژگیهای مهم YOLO است، چشمپوشی کنیم.
در بخشهای ابتدایی، یکی از ویژگیهای مثبتی که برای YOLO برشمردیم، قابلیت تعمیمپذیری آن بود. ادعا شده بود که YOLO در دادههای با توزیع متفاوت عملکرد خوبی دارد و میتواند تعمیمپذیری بالای خود را به رخ دیگر سیستمها بکشد! شکل زیر نشان میدهد که چگونه دقت سایر سیستمهای تشخیص بهشدت افت میکند. البته، در مقاله درباره تعمیمپذیری توضیحات بیشتری داده شده است که درصورت تمایل میتوانید مطالعه کنید.

به پایان مقاله سیستم تشخیص اشیای YOLO رسیدیم. امیدواریم شما تا پایان این مقاله طولانی را مطالعه کرده باشید. اگرچه YOLOv۱ مقاله بسیار خوبی بود، اما مقالههای YOLOv۲ و YOLOv۳ از YOLOv۱ بسیار بهتر هستند.