

در این مقاله میخواهیم به سیستم تشخیص اشیای YOLO نسخه اول بپردازیم. YOLOv۱ در سال ۲۰۱۶ در کنفرانس CVPR ارائه شد و تا زمان نگارش این مقاله ۴۲۷۹ ارجاع داشته است. این مقاله، ساختار جدیدی را برای سیستمهای تشخیص اشیا ارائه داد و بههمین دلیل بسیار مورد توجه قرار گرفت. سعی کردهایم برای نگارش این مقاله از مقاله اصلی YOLOv۱ حداکثر استفاده را ببریم و تمامی توضیحات را بر اساس متن مقاله اصلی ارائه دهیم. زمان زیادی برای نگارش این مقاله صرف شد و البته زمان زیادی هم برای مطالعه این مقاله نیاز هست. امیدواریم که این مقاله مفید واقع شود.
انسان با نگاهی کوتاه به تصویر بلافاصله میفهمد چه اشیایی در تصویر وجود دارند، موقعیتشان در تصویر کجاست و حتی چه ارتباطی با هم دارند. این عملها برای انسان بسیار ساده هست و سیستم بینایی دقیق و سریع انسان کارهای بهمراتب پیچیدهتری مانند رانندگی را میتواند بهآسانی انجام دهد. البته، بخش مهمی از رانندگی، شناسایی و موقعیتیابی اشیای اطراف خودرو هست که انسان در این زمینه مهارت بالایی دارد. حال، اگر الگوریتمهای سریع و دقیقی برای شناسایی و موقعیتیابی اشیا داشته باشیم، میتوان امیدوار بود که ماشینهای خودرانِ بدون نیاز به سنسورهای مخصوص داشته باشیم. شناسایی و موقعیتیابی اشیا ازجمله زمینههای تحقیقاتی قدیمی و مهم در بینایی کامپیوتر است. در بینایی کامپیوتر، به شناسایی و موقعیتیابی اشیا در تصویر Object Detection گفته میشود. معمولا در فارسی بجای عبارت شناسایی و موقعیتیابی اشیا از عبارت “تشخیص اشیا” استفاده میشود. در این مقاله، میخواهیم بهیکی از سیستمهای سریع و دقیق تشخیص اشیا بهنام YOLO بپردازیم.
YOLO مخفف عبارت You Only Look Once، بهمعنای “شما فقط یکبار به تصویر نگاه میکنید” هست. درواقع، این عبارت به همان قابلیت سیستم بینایی انسان اشاره دارد که با یک نگاه عمل تشخیص اشیا را انجام میدهد. بنابراین، سیستم تشخیص اشیای YOLO با هدف ارائه روشی مشابه کارکرد سیستم بینایی انسان طراحی شده است. اما سوال اینجاست که سیستمهای تشخیص اشیای قبل از YOLO چه ویژگیهایی داشتند و چگونه کار میکردند؟ یعنی آنها شباهتی به سیستم بینایی انسان نداشتند؟ در ادامه به این سوالها پاسخ خواهیم داد.
سیستمهای تشخیص اشیای پیش از YOLO، از کلاسیفایرها در کار تشخیص اشیا استفاده میکردند. این سیستمها برای تشخیص یک شی، یک کلاسیفایر را در موقعیتها و مقیاسهای مختلف به تصویر ورودی اعمال میکردند. بهعنوان مثال، سیستمهایی مانند Deformable Part Models یا DPM از پنجرههای لغزان (Sliding Window) بهره میبرند که کلاسیفایر را به موقعیتهای مختلف در سراسر تصویر اعمال میکنند. این اعمال کلاسیفایر به موقعیتهای مختلف تصویر، کار زمانبری است که البته شباهت چندانی هم به سیستم بینایی انسان در تشخیص اشیا ندارد. در شکل زیر، نمونهای از الگوریتمهای مبتنی بر پنجره لغزان را مشاهده مینمایید.
شکل ۱: الگوریتم تشخیص اشیا مبتنی بر پنجره لغزان

دسته دیگری از رهیافتها که نسبت به DPM جدیدتر هستند، رهیافتهای مبتنی بر پروپوزال ناحیه (Region Proposal) مانند R-CNN است. در شکل ۲، ساختار یک الگوریتم مبتنیبر پروپوزال ناحیه بهنام R-CNN را مشاهده مینمایید. در این روشها، ابتدا مجموعه زیادی پروپوزال یا همان باکس برای هر تصویر تولید میشوند (مثلا ۲۰۰۰ پروپوزال برای هر تصویر در مرحله ۲ شکل ۲). سپس، هریک از پروپوزالها به یک سایز مشخص ریسایز میشوند و برای استخراج ویژگی در اختیار شبکههای CNN قرار میگیرند (مرحله ۳ در شکل ۲). درنهایت، یک کلاسیفایر برای کلاسیفایکردن این باکسهای تولیدشده بهکار برده میشود (مرحله ۴ در شکل ۲). بنابراین، بههمین دلیل است که گفتیم روشهای تشخیص اشیای پیش از YOLO عمل تشخیص اشیا را با کلاسیفایرها انجام میدهند. این مسیر پیچیده سرعت پایینی دارد و بهینهسازی آن مشکل است، چون هریک از این اجزا که در شکل ۲ مشاهده میکنید، باید بهصورت جداگانه آموزش داده شوند.
شکل ۲: ساختار کلی الگوریتم تشخیص اشیا
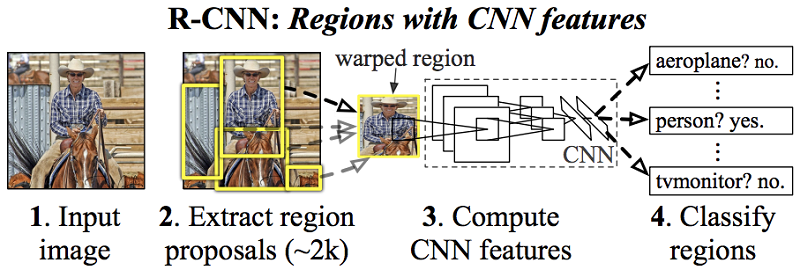
R-CNN
حال که کمی با کارکرد کلی سیستمهای تشخیص اشیای پیش از YOLO آشنا شدیم، بهتر است به YOLO برگردیم. YOLO معماری سیستمهای تشخیص اشیا را دستخوش تغییراتی کرده است و به مساله تشخیص اشیا بهصورت یک مساله رگرسیون مینگرد که مستقیم از پیکسلهای تصویر به مختصات باکس و احتمال کلاسها میرسد (در بخشهای بعدی متوجه خواهید شد که چرا میگوییم رگرسیون). با استفاده از سیستم YOLO، برای تشخیص اشیای موجود در تصویر، به هر تصویر شما فقط یک بار مینگرید (You Only Look Once). این رویکرد را با رویکردهای DPM و R-CNN مقایسه کنید.
YOLO بسیار ساده است (به شکل ۳ نگاه کنید). تنها یک شبکه کانولوشنی وجود دارد که تصویر ریسایز ورودی را دریافت (مرحله ۱) و سپس به صورت همزمان چندین باکس را به همراه احتمال کلاسها پیشبینی میکند (مرحله ۲). YOLO روی تصاویر کامل آموزش میبیند و مستقیما کارآیی تشخیص را بهبود میدهد.
شکل ۳: ساختار کلی سیستم تشخیص اشیای YOLO

مدل یکپارچه YOLO مزایای زیادی نسبت به روشهای سنتی تشخیص اشیا دارد که در ادامه اشاره خواهد شد:
- اول، YOLO بسیار سریع است. در اینجا، تنها یک شبکه وجود دارد که خیلی ساده به آن ورودی تصویر داده میشود تا شبکه پیشبینیهای تشخیص اشیا را به ما نشان دهد. دو نسخه شبکه YOLO شامل YOLO اصلی و YOLO سریع طراحی شده است. YOLO اصلی با کارت گرافیک Titan X با سرعت ۴۵ فریمبرثانیه اجرا میشود. نسخه سریع YOLO هم سرعتی بیش از ۱۵۰ فریمبرثانیه دارد. یعنی YOLO میتواند در یک ویدئوی ۴۰ فریمبرثانیه درحالت بلادرنگ به تشخیص اشیا بپردازد. YOLO نسبت به دیگر سیستمهای تشخیص اشیای بلادرنگ، به mAP یا همان mean Average Precision دوبرابر دست یافته است. دقت کنید، عملکرد بهتر نسبت به سایر سیستمهای بلادرنگ و نه سیستمهای تشخیص اشیای قدرتمند مانند Faster R-CNN که بلادرنگ نیستند.
- دوم، YOLO برای پیشبینی تشخیص، به صورت کلی (Global) به تصویر نگاه میکند. برخلاف تکنیکهای پنجرههای لغزان (اسلاید) و پروپوزال، YOLO به کل تصویر نگاه میکند.
- سوم، YOLO تعیمیمپذیری بالایی دارد. زمانیکه تصاویر به شبکه آموزش داده میشوند و سپس شبکه آموزشدیده روی کارهای هنری تست میشود (در واقع منظورمان همان تغییر حوزه دادههای ورودی است) شبکه YOLO با فاصله زیادی بهتر از شبکههایی مانند DPM و R-CNN کار میکند. بنابراین، YOLO به شدت تعمیمپذیر هست و در مقابل حوزههای جدید و یا دادههای ورودی غیرمنتظره با احتمال کمتری نسبت به بقیه سیستمها با شکست مواجه میشود.
YOLO همچنان از سیستمهای تشخیص اشیای مدرن در دقت عقب هست. درحالیکه YOLO سرعت بالایی در تشخیص اشیا دارد، اما در تعیین دقیق بعضی از اشیا در تصویر، خصوصا اشیای کوچک چالش دارد. درادامه، درمورد ساختار کلی سیستم تشخیص اشیای YOLO توضیح خواهیم داد.
ساختار کلی YOLO
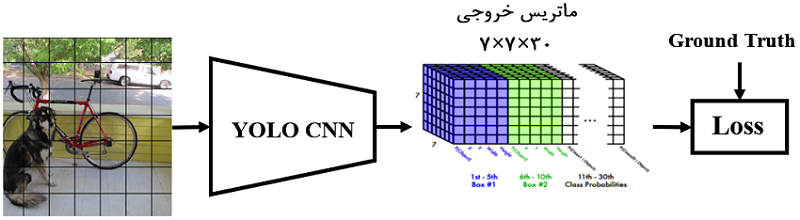
ساختار کلی سیستم تشخیص اشیای YOLO در شکل ۴ نشان داده شده است. تصویر ورودی با ابعاد ۳×۴۴۸×۴۴۸ به یک Grid یا شبکه S×S تقسیمبندی میشود. این تصویر به شبکه YOLO داده میشود. خروجی شبکه، ماتریسی به ابعاد ۳۰×S×S خواهد بود. هریک از درایههای ماتریس S×S خروجی معادل با یک سلول در شبکه S×S ورودی است (به ورودی و خروجی در شکل ۴ دقت کنید). خروجی ۳۰×S×S شامل مختصات باکسها و احتمالهاست. اگر در فرآیند آموزش (Train) باشیم، خروجی ۳۰×S×S بههمراه باکسهای واقعی یا هدف (Ground Truth) به تابع اتلاف داده میشود. مقدار S در یولو نسخه ۱، برابر با ۷ درنظر گرفته شده است. اگر در فرآیند آزمایش (Test) باشیم، خروجی ۳۰×S×S به الگوریتم حذف غیرحداکثرها (Non-maximum Suppression) داده میشود تا باکسهای ضعیف از بین بروند و تنها باکسهای درست در خروجی نمایش داده شوند. درادامه، درمورد طراحی شبکه YOLO، نحوه آموزش شبکه، تابع اتلاف، آزمایش شبکه و غیره توضیح خواهیم داد.
شکل ۴: ساختار کلی سیستم YOLO همراه با ورودی و خروجی
طراحی شبکه
YOLO شامل یک شبکه عصبی کانولوشنی (Convolutional Neural Network) با ۲۴ لایه کانولوشنی برای استخراج ویژگی و همچنین ۲ لایه فولیکانکتد (Fully Connected) برای پیشبینی احتمال و مختصات اشیا است. معماری شبکه کانولوشنی YOLO را در شکل ۵ مشاهده میکنید.
شکل ۵: معماری شبکه YOLO همراه با ۲۴ لایه کانولوشنی
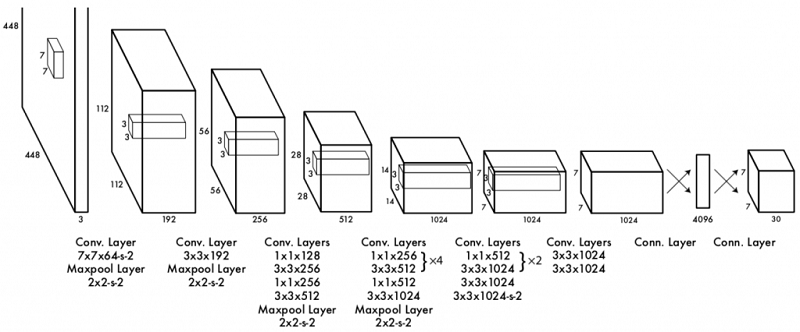
همچنین، یک نسخه سریع از YOLO برای جابجایی مرزهای تشخیص اشیای سریع طراحی شده است. YOLO سریع، یک شبکه عصبی با تعداد لایههای کانولوشنی کمتر است که در آن از ۹ لایه کانولوشنی بجای ۲۴ لایه کانولوشنی (YOLO اصلی) استفاده شده و البته تعداد فیلترهای هر لایه در YOLO سریع نسبت به YOLO اصلی کمتر است. اندازه ورودی هر دو شبکه ۳×۴۴۸×۴۴۸ و خروجی شبکه نیز یک تنسور ۳۰×۷×۷ از پیشبینیها است. درتمامی لایهها از Leaky ReLU استفاده شده است. ممکن است سوالاتی درمورد اندازه ورودی و خروجی شبکه YOLO داشته باشید. مثلا، چرا ابعاد ورودی ۳×۴۴۸×۴۴۸ است، درحالیکه اکثر شبکههای کانولوشنی ورودی حدودا ۳×۲۲۴×۲۲۴ دارند؟ چرا خروجی ۳۰×۷×۷ است و این خروجی شامل چه اطلاعاتی است؟ چگونه از این خروجی، پیشبینی احتمالها و مختصات باکس اشیا استخراج میشود؟ درادامه، در بخش بعدي آموزش شبکه به این سوالات پاسخ خواهیم داد.