
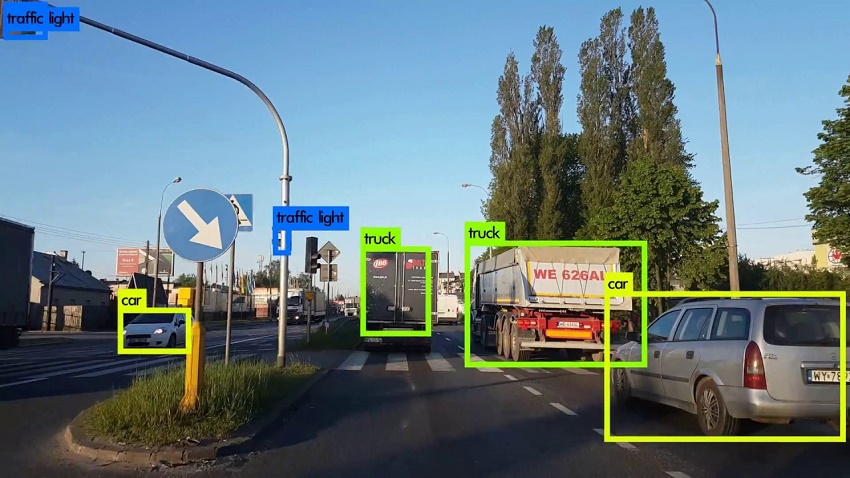
در فناوریهای مبتنی بر تشخیص اشیا، روی دو وظیفه (دامنه کاربردی) عمده در سیستمهای بینایی کامپیوتر تمرکز خواهد شد؛ دستهبندی تصاویر و تشخیص اشیا در تصاویر.
سیستمهای دستهبندی تصاویر روی دستهبندی (گروهبندی) تصاویر در طبقهها یا کلاسهای از پیش تعیین شده تمرکز دارند. برای پیادهسازی چنین سیستمهایی، ابتدا باید تصاویری که در کلاسهای مورد نظر دستهبندی میشوند، در اختیار سیستم قرار داده شود. سپس، سیستم با استفاده از این تصاویر «آموزش» (Train) داده میشود. مدل آموزش داده شده قادر خواهد بود تا با تحلیل «ویژگیهای» (Features) تصویر، کلاس یا طبقه تصاویر را مشخص کند. به عنوان نمونه، در صورتی که تصویر حاوی گربه وارد سیستم شود، آن را در کلاس گربه دستهبندی میکند.
سیستمهای تشخیص اشیا از مدلهای دستهبندی تصاویر استفاده میکنند تا مشخص کنند چه چیزهایی در یک تصویر و در کجای آن قرار دارند. چنین کاربردهایی از سیستمهای بینایی کامپیوتر، از طریق استفاده مدلهای یادگیری عمیق (شبکه عصبی) نظیر شبکههای عصبی پیچشی امکانپذیر شدهاند. استفاده از چنین مدلهایی برای تشخیص اشیا به سیستمهای بینایی کامپیوتر اجازه میدهند تا یک تصویر را در چندین کلاس دستهبندی کنند؛ وجود چندین شیء را در تصویر تشخیص دهند.

در این مطلب و برای پیادهسازی سیستم تشخیص اشیا، از چالش Google AI Open Image که به میزبانی Kaggle برگزار میشود استفاده شده است. هدف این چالش، تشخیص اشیا گوناگون، در تصاویر مختلف و بعضا پیچیده است. در این چالش، از یک مجموعه داده متشکل از ۱٫۷ میلیون تصویر استفاده شده است. اشیاء موجود در تصاویر این مجموعه داده، به وسیله ۱۲ میلیون «کادر محصور کننده» (Bounding Box) در ۵۰۰ کلاس مختلف دستهبندی شدهاند ( به هر کدام از تصاویر موجود در مجموعه داده، چندین کادر محصور کننده برای تشخیص اشیا مشخص شده است). از جمله مهمترین ویژگیهای این مجموعه داده، میتوان به موارد زیر اشاره کرد:
• ۱۲ میلیون «کادر محصور کننده» (Bounding Box) برای دستهبندی ۱٫۷ میلیون تصویر در ۵۰۰ کلاس مختلف.
• تصاویر با صحنههای پیچیده که در برگیرنده چندین شیء مختلف هستند؛ به طور متوسط ۷ کادر محصور کننده به ازاء هر تصویر.
• تصاویر بسیار متنوع که حاوی اشیاء مختلف و متمایز هستند.
• سلسله مراتبی مناسب برای کلاسها، که منعکس کننده روابط میان کلاسهای این مجموعه داده است


تحلیل اکتشافی دادهها
پیش از پیادهسازی سیستم تشخیص اشیا در تصویر، دادههای تصویری لازم برای آموزش مدل مورد بررسی قرار میگیرند تا کلاسهای قابل تشخیص در تصاویر مشخص شوند.
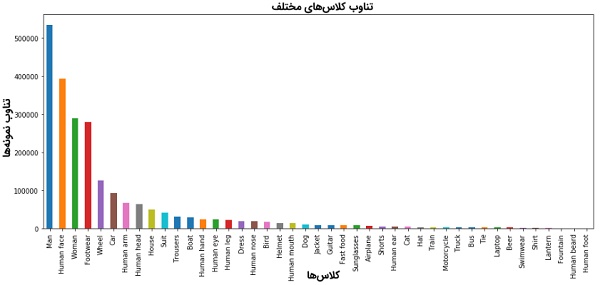
با بررسی اجمالی تصاویر آموزشی مشخص میشود که تناوب برخی از کلاسهای موجود در مجموعه داده، به مراتب بالاتر از سایر کلاسها است. نمودار بالا، توزیع ۴۳ کلاس متناوب در مجموعه داده Open Image را نشان میدهد. همانطور که مشاهده میشود، توزیع نمونههای موجود در کلاسهای مختلف نابرابر است؛ مشکلی که برای آموزش بهینه سیستم تشخیص اشیا، به نحوی باید برطرف شود. برای متعادل کردن تناوب دادههای آموزشی هر کلاس، رویه زیر اتخاذ شده است:
• برای آموزش سیستم تشخیص اشیا، تنها از دادههای موجود در ۴۳ کلاس متناوب در مجموعه داده Open Image استفاده میشود (در مجموع، ۳۰۰ هزار تصویر در این ۴۳ کلاس وجود دارند).
• برای متعادل کردن تناوب دادههای آموزشی هر کلاس، از هر کلاس تنها ۴۰۰ تصویر به طور تصادفی انتخاب و در مجموعه آموزشی قرار داده میشود (در مجموع، ۱۷۲۰۰ تصویر برای پیادهسازی سیستم تشخیص اشیا استفاده شده است).
انتخاب الگوریتم تشخیص اشیا
الگوریتمهای مختلفی برای پیادهسازی سیستم تشخیص اشیا در نظر گرفته شدند، اما در نهایت، الگوریتم YOLO به عنوان الگوریتم اصلی بر پیادهسازی این سیستم در نظر گرفته شد. دلیل انتخاب الگوریتم YOLO، سرعت بالا و قدرت محاسباتی آن و همچنین، وجود منابع آموزشی زیاد برای راهنمایی کاربران هنگام پیادهسازی این الگوریتم است. به دلیل محدودیتهای محاسباتی و زمانی، تصمیمات زیر جهت طراحی و پیاده شبکه عصبی (برای کاربرد تشخیص اشیا) اتخاذ شد:
۱. از یک مدل YOLO V۲ که پیش از این برای شناسایی اشیاء خاصی آموزش دیده شده است، استفاده میشود (یک مدل یادگیری عمیق از پیش آموزش داده شده).
۲. از قدرت مفهوم «یادگیری انتقال» (Transfer Learning) استفاده میشود و لایه کانولوشن (پیچشی) آخر مدل YOLO دوباره آموزش داده میشود تا سیستم تشخیص اشیا بتواند اشیائی را که پیش از با آنها برخورد نداشته است (Unseen Objects)، نظیر گیتار، خانه، مرد، زن، پرنده و سایر موارد، تشخیص دهد.
مشخصات ورودیهای مدل YOLO برای تشخیص اشیا
الگوریتم YOLO برای اینکه بتواند اشیاء موجود در تصویر را تشخیص دهد، ورودیهای خاصی را میپذیرد:
۱. ابعاد تصاویر ورودی: شبکه YOLO به گونهای طراحی شده است تا با تصاویری که ابعاد مشخصی دارند آموزش ببیند. ابعاد تصویر استفاده شده برای آموزش شبکه YOLO، برابر با ۶۰۸×۶۰۸ است.
۲. تعداد کلاسها: برابر ۴۳ کلاس است. تعداد کلاسها، پارامتری است که برای تعریف ابعاد خروجیهای شبکه YOLO مورد نیاز است.
۳. پارامترهای Anchor Box: تعداد کادرهای محصور کننده یا Bounding Box و همچنین ابعاد بیشینه و کمینه آنها؛ به مجموعه این اطلاعات، پارامترهای Anchor Box گفته میشود.
۴. حد آستانه برای معیارهای IoU (معیار Intersection over Union) و ضریب اطمینان (Confidence): این حد آستانه به این دلیل تعریف شده است تا مشخص شود کدام یک از کادرهای محصور کننده، باید به عنوان کادرهای در بر گیرنده اشیاء موجود در تصویر انتخاب شوند (انتخاب میان کادرهای محصور کننده).
۵. اسامی تصاویر به همراه اطلاعات پارامترهای Anchor Box: به ازاء هر تصویر، نیاز است تا اطلاعاتی همانند اطلاعات تعبیه شده در شکل زیر در اختیار شبکه YOLO قرار گرفته شود.

معماری شبکه YOLO V۲
معماری شبکه YOLO V۲ در شکل زیر نمایش داده شده است. این شبکه، از ۲۳ لایه کانولوشن (پیچشی) تشکیل شده است؛ هر کدام از این لایهها، واحد «نرمالسازی دستهای» (Batch Normalization)، تابع فعالسازی Leaky RELU و واحد Max Pooling مختص به خود را دارد.
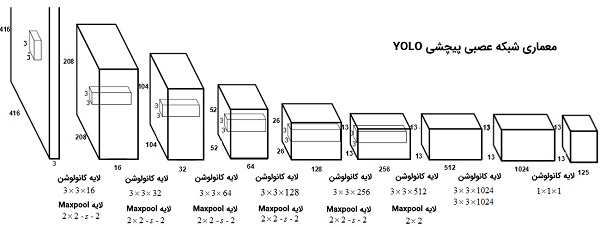
هدف لایههای تعریف شده، استخراج چندین ویژگی مهم از تصاویر دیجیتالی است تا از این طریق، سیستم تشخیص اشیا قادر باشد اشیاء مختلف موجود در تصویر را تشخیص دهد و آنها در کلاسهای متناظر دستهبندی کند. با هدف تشخیص اشیا موجود در تصویر، الگوریتم YOLO تصویر را به یک گرید (Grid) متشکل از سلولهای ۱۹×۱۹ تقسیمبندی میکند؛ به ازاء هر سلول تشکیل شده در گرید، پنج کادر محصور کننده با ابعاد متفاوت تعریف میشود. سپس شبکه YOLO تلاش میکند تا کلاس اشیاء موجود در سلولهای گریدی را تشخیص دهد؛ به عبارت دیگر، احتمال تعلق هر کدام از اشیاء شناسایی شده (درون کادرهای محصور کننده هر سلول) به کلاسهای موجود در مجموعه داده محاسبه میشود.
هر کدام از کادرهای محصور کننده، ابعاد و اشکال متفاوتی نسبت به یکدیگر دارند و در اصل ، برای تشخیص دادن اشیاء گوناگون (با شکلها و ابعاد مختلف) در هر یک از سلولهای گریدی طراحی شدهاند. خروجی الگوریتم YOLO ماتریسی به شکل زیر است؛ به ازاء هر کدام از کادرهای محصور کننده تعریف شده (در هر کدام از سلولهای گریدی)، ماتریسی مشابه شکل زیر تولید خواهد شد.
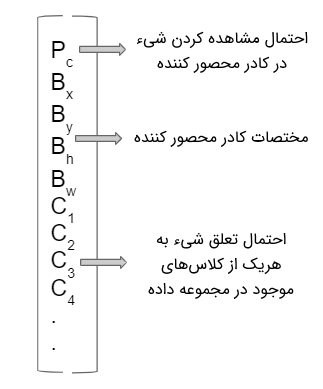
از آنجایی که شبکه YOLO با استفاده ار تصاویر ۴۳ کلاس آموزش داده میشود، ابعاد ماتریس خروجی به شکل زیر محاسبه میشود.

این ماتریس اطلاعات بسیار مهمی نظیر «احتمال مشاهده شدن یک شیء در هر یک از کادرهای محصور کننده» (Probabilities of Observing an Object for Each Anchor Box) و احتمال تعلق شیء شناسایی شده در کارد محصور کننده، به هر کدام از کلاسهای از پیش تعریف شده را، در اختیار قرار میدهد. برای اینکه کادرهای بدون شیء (کادرهایی که هیچ شیء خاصی در آنها وجود ندارد)، کادرهایی که شیء شناسایی شده در آنها در هیچ کلاسی دستهبندی نمیشود یا کادرهایی که شیء شناسایی شده در آنها با کادرهای دیگر همپوشانی دارند، فیلتر شوند ار دو حد آستانه زیر استفاده میشود:
• حد آستانه IoU: برای فیلتر کردن کادرهایی به کار میرود که یک شیء واحد و یکسان در آنها شناسایی شده است.
• حد آستانه ضریب اطمینان (Confidence): برای فیلتر کردن کادرهایی به کار میروند، احتمال تعلق آنها به کلاسهای مختلف بسیار پایین است.
قطعه کد زیر، نحوه تعریف لایههای مختلف شبکه YOLO جهت تشخیص اشیا را نشان میدهد:
یادگیری انتقال
یادگیری انتقال، مفهومی است که در آن از یک شبکه عصبی از پیش آموزش داده شده (جهت دستهبندی تصاویر)، برای مقاصد دیگر (نظیر دستهبندی و تشخیص اشیا که در این مطلب آموزش داده میشود) استفاده میشود. روش کار بدین صورت است که جهت یادگیری انتقال، مدل از پیش آموزش داده شده توسط دادههای جدید و به وسیله پارامترهای متناسب با این دادهها، «آموزش دوباره» (Re-Train) داده میشود (تعدادی از پارامترهای وزن شبکه عصبی در نتیجه چنین فرایندی، از دوباره تنظیم میشوند). از آنجایی که در انتقال یادگیری نیاز به یادگیری و تنظیم تعداد زیادی پارامتر وزن وجود ندارد، چنین کاری باعث صرفهجویی بسیار زیاد در زمان و قدرت محاسباتی لازم برای آموزش شبکه عصبی میشود.
به عنوان نمونه، شبکه عصبی از پیش آموزش داده شده که در این مطلب استفاده شده است، چیزی حدود ۵۰ میلیون پارامتر وزن دارد. یادگیری چنین مدلی در پلتفرمهای قدرتمند محاسبات ابری نظیر Google Cloud، حداقل به ۴ الی ۵ روز زمان نیاز دارد. برای اینکه از مفهوم یادگیری انتقال، با موفقیت، برای آموزش دوباره شبکه عصبی (روی دادههای جدید) استفاده شود، لازم است که برخی از پارامترها و تنظیمات مدل بهروز رسانی شوند تا مدل آموزش از پیش داده شده بتواند خود را با دادههای جدید وفق دهد:
ابعاد تصاویر ورودی: ابعاد تصاویر ورودی در مدل YOLO از پیش آموزش داده شده، برابر با ۴۱۶×۴۱۶ است. از آن جایی که تصاویر استفاده شده در این مطلب، ابعاد بزرگتری نسبت به تصاویر استفاده شده در مدل YOLO از پیش آموزش داده شده دارند و همچنین، ابعاد برخی از اشیائی که قرار است شناسایی شوند بسیار کوچک است (نظیر کفش، پرنده و سایر موارد)، منطقی نیست که ابعاد تصاویر جدید تا ابعاد ۴۱۶×۴۱۶ کاهش پیدا کنند. به همین خاطر، ابعاد تصاویر جدید برای آموزش دوباره مدل YOLO، برابر با ۶۰۸×۶۰۸ در نظر گرفته شده است.
اندازه گرید (Grid): در مدل YOLO از پیش آموزش داده شده، ابعاد سلولهای گرید برابر با ۱۳×۱۳ است. در این مطلب، ابعاد سلولهای گرید، جهت آموزش دوباره مدل YOYO، به ۱۹×۱۹ تغییر پیدا کرده است.
لایه خروجی: تعدادکلاسها در مدل YOLO از پیش آموزش داده شده، برابر با ۸۰ است. در حالی که برای آموزش دوباره مدل، از دادههای ۴۳ کلاس استفاده شده است. بنابراین، لازم است تغییراتی در ابعاد لایه خروجی ایجاد شود تا سیستم بتواند خود را با کلاسهای جدید، دادههای آنها و الگوهای موجود در آنها وفق دهد.
برای اینکه بتوان مدل YOYO را روی دادههای تصویری جدید آموزش داد، نیاز است تا پارامترهای وزن لایه کانولوشن (پیچشی) آخر از دوباره مقدار دهی اولیه شوند؛ چنین کاری به سیستم اجازه میدهد تا تصاویر متعلق به کلاسهای خاص (و جدید) را به درستی دستهبندی کند.
جمعبندی
تشخیص اشیا متفاوت از دیگر کاربردهای بینایی کامپیوتر است. این امکان برای محققان و علاقهمندان به این حوزه وجود دارد تا یک مدل از پیش آموزش داده شده را مورد استفاده قرار دهند و تغییرات متناسب با کاربرد مد نظرشان روی این مدل اعمال کنند تا برای تشخیص اشیا و دستهبندی آنها استفاده شود. برای آموزش چنین مدلهایی، دادههای آموزشی بسیار زیاد و زمان و قدرت محاسباتی قابل توجهی مورد نیاز است. بنابراین توصیه میشود که از پلتفرمهای محاسبات ابری نظیر Google Cloud Platform برای آموزش مدلهای تشخیص اشیا استفاده شود.
در هنگام پیادهسازی چنین سیستمهایی، ابتدا از تمامی دادههای موجود در ۵۰۰ کلاس مجموعه داده Open Images استفاده شد. با این حال، پس از پایان مرحله آموزش مدل و در جریان تست مدل تشخیص اشیا مشخص شد که مدل آموزش داده شده قادر به پیشبینی کلاس صحیح بسیاری از تصاویر تست نبود. دلیل این امر این بود که فراوانی نمونههای موجود در کلاسهای مختلف نابرابر بود؛ به عبارت دیگر مجموعه داده استفاده شده «نامتعادل» (Imbalance) بود.
بنابراین، برای اینکه تعادل میان نمونههای مختلف موجود در کلاسها برقرار شود، تصمیم بر این شد تا از دادههای ۴۳ کلاس متناوب در مجموعه داده Open Images، برای آموزش مدل استفاده شود. با اینکه این رویکرد، رویکرد مناسبی برای متعادل کردن دادههای آموزشی نیست، ولی به سیستم اجازه میدهد تا روی مجموعه دادهای آموزش ببیند که در آن، تعداد نمونههای برابری از کلاسهای مختلف حضور دارند.
تشخیص اشیا یکی از موضوعات چالشبرانگیز در حوزه هوش مصنوعی و بینایی کامپیوتر محسوب میشود. با این حال، به دلیل جذابیت بالای این حوزه برای محققین و ملموس و قابل حس بودن نتایج آن (درک خروجی سیستم و نتایج حاصل از آن، حتی برای کاربران عادی، بسیار راحت است)، توجه محققان حوزه بینایی کامپیوتر را به خود معطوف کرده است.
از همه مهمتر، سیستمهای تشخیص اشیا یکی از مؤلفههای اساسی در فناوریهای نوظهور نظیر اتومبیلهای خودران و احراز هویت بیومتریک توسط دوربین به حساب میآید. همچنین، با توجه به اینکه منابع آموزشی بسیار زیادی برای یادگیری و تحقیق در این حوزه در اختیار علاقهمندان قرار گرفته شده است، یادگیری مفاهیم این حوزه و به دست آوردن تخصص در این زمینه، فرصتهای شغلی جذابی را در اختیار علاقهمندان به این حوزه قرار میدهد.