
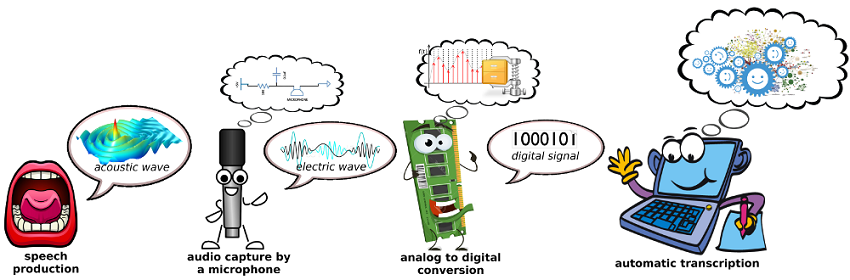
مراحل کلی تشخیص صوت به شرح زیر است:
آماده سازی سیگنال: اولین قدم در آماده سازی سیگنال گفتار و پردازش آن، تبدیل آن از فرم آنالوگ به فرم دیجیتال است. گفتاری که به وسیله انسان بیان می شود، به صورت یک موج در هوا انتشار می یابد . این موج توسط میکروفون دریافت و به سیگنال الکتریکی که یک سیگنال آنالوگ و دارای تغییرات پیوسته در زمان است تبدیل می شود. رقمی سازی نتیجه گسسته سازی سیگنال در حوزه زمان و دامنه است. رقمی کردن گفتار باعث کاهش حجم ذخیره سازی، پردازش و انتقال آسانتر و کاهش هزینه می شود. وقتی یک سیگنال آنالوگ به رقمی تبدیل می شود، هم در زمان و هم در اندازه گسسته می شود.
نمونه برداری: نمونه برداری به معنای عملی است که توسط آن سیگنال آنالوگ گفتار به یک سری نمونه ها تبدیل می شود.
چندی کردن: چندی کردن بر روی نمونه های سیگنال صورت می گیرد. چندی کردن، سیگنال را در حوزه دامنه گسسته می نماید .هر چه تعداد سطوح چندی کردن بیشتر باشد، سیگنال به سیگنال آنالوگ اصلی نزدیکتر می شود . به تعداد بیت مورد استفاده برای چندی کردن رزولوشن یا دقت چندی سازی گفته می شود . پایین بودن دقت چندی سازی موجب می شود که نتوان پارامتر شیمر را به درستی محاسبه نمود.
استخراج ویژگی ها: استخراج بهترین نماینده پارامتری از میان سیگنال های صوتی، یکی از وظایف مهم برای داشتن بهترین عملکرد است. انجام نتیجه گیری درست این مرحله برای عملیاتی شدن فازهای دیگر تاثیر خواهد داشت.
انتخاب استراتژی شناسایی و تشخیص صوت: در این مرحله یکی از روش های تشخیص صدا نظیر شبکه عصبی؛ ماشین SVM یا ..... انتخاب و بر اساس روشها و متدولوژی های مرتبط سیگنال های ورودی مورد پردازش قرار می گیرند.

معرفی برخی روش ها و رویکردها:
تطابق الگو: تکنیکی است که از ورودی های کاربر استفاده می نماید و وابسته به آن است که کاربر از چه متدی استفاده نماید. دارای بیشترین دقت است .دقتی در حدود ۹۹ ٪ ولی محدودیت های بسیاری را داراست . این الگوریتم به این شکل آغاز به کار می نماید که از کاربر درخواست پخش صدا در میکروفن را می کند. صدا ها مکررا تکرار می شوند و متوسط معیار ها به عنوان نمونه ذخیره می شود. زمانی که صدایی به عنوان ورودی از میکروفن و به شکل سیگنالی دیجیتال دریافت می شود، تبدیل شده و در حافظه ذخیره می گردد سیگنال های ذخیره شده با نمونه ها مقایسه می شوند و منطبق ترین به عنوان خروجی بازگردانده می شوند.
مبتنی بر مدل مخفی مارکوف: تشخیص صدا یا شناسایی گوینده یکی از مسایل علوم رایانه و هوش مصنوعی است که هدف آن شناسایی یک فرد تنها از روی صدای شخص است. یکی از اصلیترین ابزارهای ریاضی برای حل این مسئله مدل های پنهان مارکوف هستند. برای حل این مسئله با استفاده از مدل پنهان مارکوف این مدل های آماری ابتدا باید مورد آموزش قرار بگیرند. برای این مرحله ابتدا مقدار قابل توجهی از صدای ضبط شده افراد پردازش میشود. داده های پردازش شده که در حقیقت مجموعه عظیمی از اعداد میباشند متناوبا مورد استفاده قرار می گیرند تا مدل پنهان مارکوف، برای هر گوینده به دست آید. در حقیقت مدل پنهان مارکوف مانند یک ماشین عمل میکنند که ورودی آنها یک سری داده است و خروجیشان یک عدد برای هر مجموعه ای از داده ها، به این صورت که آن عدد نشان دهنده اختلاف داده های ورودی با مدل پنهان مارکوف هر ماشین است. برای آموزش مدل پنهان مارکوف در هر تناوب داده ها به مدل پنهان مارکوف داده میشود و پارامترهای مدل پنهان مارکوف ذره ای تغییر داده میشود تا عدد خروجی که نشان دهنده اختلاف داده ها با مدل پنهان مارکوف است کوچکتر شود. برای اطمینان از اینکه تغییر پارامترهای مدل پنهان مارکوف در جهت درست انجام می گیرد و نهایتا به حداقل شدن عدد خروجی می انجامد از یک روش ریاضی استفاده می شود. در نهایت بعد از آموزش این مدلها که با استفاده از صدای مرجع انجام شده، می توان برای آزمایش سامانه صدای یکی از افرادی که قبال از صدای وی برای آموزش مدل پنهان مارکوف استفاده شده را به هر یک از مدل های پنهان مارکوف داد مدل پنهان مارکوف ای که کوچکترین عدد را تولید می کند به عنوان فرد شناسایی شده در نظر گرفته میشود.
مدل های ترکیبی: از مدل اصلی کانال منبع و یا بخشی و یا نوعی از مدل های آماری مولد معمولا استفاده می شود تا مشکلات تشخیص گفتار را فرموله کنند. ذهن گوینده تصمیم می گیرد و دنباله کلمات را انتخاب می نماید و آن را از طریق ژنراتور های متن تحویل می دهد. منبع از کانال های ارتباطی پر سر و صدا که شامل بلند گوی سخنگو است که برای تولید موج های گفتار یا کلام و همچنین سیگنال های پردازشی الزم برای بازشناس گفتار است عبور می کند و در نهایت وظیفه رمز گشا است که سیگنال های صوتی X را به W رمز گشایی نماید که W ایده آل ترین حالت و نزدیک به سیگنال اصلی صوت می باشد. برنامه های کاربردی با رمز گشا مرتبط می شوند تا نتایج بازشناسی را بدست بیاورند که ممکن است آن ها را به سایز بخش های سیستم وقف دهند یا سازگار نمایند.
مدل انطباق زمانی پویا: مدلی ساده و قدیمی که در گوشی های تلفن همراه برای شماره گیری صوتی با بیان نام فرد به کار می رود.
شبکه عصبی مصنوعی: مدلی ساده و کارا با سرعت تشخیص بالا و عملکرد بالا درنگ که در برابر نویزهای محیطی مقاوم است و فرایند آموزش آن زمان بر است.

مدل آکوستیک: مسئله دقت در تشخیص گفتار بعد از سال ها تحقیق و توسعه به عنوان یکی از اساسی ترین چالش ها باقی مانده است. عوامل شناخته شده و معروفی هستند که میزان سیستم های تشخیص صوت را تعیین می کنند. از قابل توجه ترین آن ها می توان به تغییرات زمینه، تغییرات سخن گو و تغییرات محیط را برشمرد. مدل سازی آکوستیک گفتار به طور معمول برمی گردد به روند ایجاد بازنمود ها یا نمایش های آماری برای دنباله ای از بردار های ویژگی محاسبه شده از شکل موج گفتار. مدل سازی آکوستیک هم چنین شامل مدل سازی تلفظی است که در آن توضیح میدهند که چگونه یک توالی از واحد های اساسی گفتار استفاده می شود تا واحد های بزرگتری از گفتار ایجاد شوند نظیر کلمات یا عبارات که این ها هدف تشخیص گفتار هستند. مدل سازی آکوستیک هم چنین شامل استفاده از اطلاعات باز خورد از تشخیص دهنده باشد تا بردارهای ویژگی های کلام در محیط های پر سر و صدا را تغییر شکل دهد. مدل صوتی یا آکوستیک شامل بخش هایی از علم در مورد صداها و آکوستیک، فونوتیک یا آوا شناسی، تنوع زیست محیطی و تفاوت های مهم در نوع گویش سخنران است. مدل زبان مربوط به دانش یک سیستم در مورد کلمات ممکن است و اینکه چه کلماتی به احتمال زیاد در چه رشته ای از کلمات استفاده می شود. توابع و قواعد معناشناسی بسته به عملیات کاربر ممکن است در بخش مدل زبان قرار گیرند. بسیاری از ابهامات در این زمینه، در ارتباط با ویژگی های سخنران، سبک گفتار و سرعت آن، به رسمیت شناختن بخش های اساسی بیان ، كلمات ممکن یا احتمالی .کلمات متشابه، كلمات ناشناخته، تنوع گرامری، نویز و سر و صدا، لهجه های غیر بومی و ... روی نتیجه تاثیر خواهد گذاشت. یک سیستم تشخیص صوت موفق باید با تمامی ابهامات ستیزه و مقابله کند. ابهامات آکوستیک ناشی از لهجه های متفاوت و سبک های صحبت کردن هر فرد، توسط پیچیدگی ها و اختلافات لغوی و گرامری ناشی از تغییرات زبان محاوره ای که در مدل زبانی وجود دارند، تشدید می شود. سیگنال های گفتار در ماژول های پردازش سیگنال پردازش می شوند که در این مرحله بردار ویژگی های برجسته برای رمز گشا، استخراج می شود. رمزگشا از هر دو مدل آکوستیک و زبانی برای ساختن دنباله ای از کلمات که دارای اولویت بیشتری با توجه به ویژگی های استخراج شده ورودی دارند استفاده می کند.
مدل زمانی: نقش و وظیفه مدل زبانی یافتن مقدار WPدر معادله اصلی تشخیص گفتار است. این مدل یکی از انواع مدلهای زبانی گرامر با دستور زبان است که یک ساختار رسمی و مجاز برای زبان بحساب می آید. تکنیک های تجزیه یکی از انواع متدهایی است که با آن می توان جملات را آنالیز کرد و تحلیل نمود و تطابق ساختار جمله را با دستور زبان بررسی کرد. با ورود قالب های متنی که هر کدام آرای ساختار مختص به خود هستند ، امروزه امکان تعمیم دستور زبان اصلی وجود دارد. علاوه بر این روابط احتمالی میان دنباله ها را می توان به صورت مستقیم بدست آورد . Corporaیا مدل های زبانی تصادفی مانند gram - N از نیاز به ایجاد پوشش گسترده ی دستور زبان رسمی اجتناب می کنند. از انواع شایع مدل های دیگر زبان، مدل زبان های تصادفی هستند که نقش مهمی را در سیستم های زبانی گفتاری ایفا می کند.